이번에는 Protocol Type과 Generic Code의 Performance에 대한 부분입니다.
Protocol
이번에는 Protocol 타입을 활용한 코드로 살펴보겠습니다.
protocol Drawable {
func draw()
}
struct Point: Drawable {
var x, y: Double
func draw() { ... }
}
struct Line: Drawable {
var x1, y1, x2, y2: Double
func draw() { ... }
}
var drawables: [Drawable]
for d in drawables {
d.draw()
}Drawable 클래스 추상화를 대신하여 이번에는 Protocol Drawable을 사용한 모습을 볼 수 있습니다. 그리고 Value Type인 Point 구조체와 Line 구조체가 Drawable 프로토콜을 준수하고 있습니다.
class SharedLine: Drawable {
var x1, y1, x2, y2: Double
func draw() { ... }
}또한 class 타입에도 Drawable 프로토콜을 준수할 수 있습니다. 그러나 class와 함께 제공되는 의도치 않은 reference semantics 공유를 가져올 수도 있기 때문에 그러지 않기로 결정했습니다. (However we decided to because of the unintended sharing that reference semantics that comes with classes brings with it to not to do that.)
프로그램은 여전히 다형성을 가지고 있습니다. 여전히 Point 타입과 Line 타입을 Drawable 프로토콜의 배열인 drawables에 담을 수 있습니다. 그러나 이전의 클래스로 나타내었을 때의 코드와 비교해보면 한가지가 달라졌습니다.
바로 Point와 Line은 공통적인 상속 관계(common inheritance relationship)를 공유하지 않는다는 것입니다.
for d in drawables {
d.draw()
}이전의 방식은 d.draw()라는 코드는 컴파일 타임에 어떤 draw()메서드를 호출해야할지 몰랐습니다. 그래서 해당 타입의 정보를 가지고 vtable을 조회하는 과정을 거쳐 어디에 있는 draw()메서드를 호출할지 결정한다고 했었습니다. 그것을 Dynamic Dispatch라고 했었죠.
그렇다면 Protocol을 사용한 지금! VTable을 사용하지도 않고, 그렇다고 컴파일 타임에 어떤 draw()메서드가 실행되는지도 모르는 지금은 Swift는 어떤 방식으로 올바른 메서드로 dispatch를 하게될까요? (Dynamic dispatch without VTable)
정답은 Table 기반의 메커니즘인 Protocol Witness Table(PWT)를 활용하는 방법입니다.

테이블의 엔트리는 해당 타입의 실행문에 각각 연결(link)되어 있습니다. 이제 메서드를 어떻게 찾는지 알아냈습니다! 그럼 다음 의문이 생기게 됩니다. "그럼 배열의 원소에서 Table로 찾아가는 방법은 뭘까?"
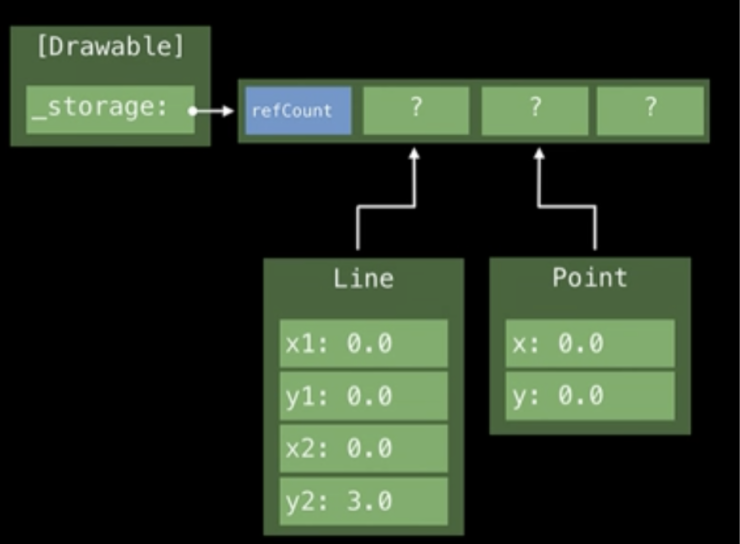
그림에서 보이듯 Line과 Point가 차지하는 Size는 다릅니다. Line은 현재 4칸을 차지하고 있고, Point같은 경우에는 2칸을 차지하고 있네요! Line과 Point는 서로 같은 크기를 가질 필요가 없다는 것입니다. 하지만 우리의 Array는 각각의 요소를 균등하게(uniformly) 고정된 offset에 저장하려고 합니다. 이러한 과정이 어떻게 동작할까요?
Swift는 특별한 Storage Layout 을 사용합니다. 바로 Existential Container이죠. 여기에 뭐가 들어있을까요?

우선 처음 3칸에는 valueBuffer가 들어갑니다. 작은 타입 즉 Point의 x, y와 같은 2칸만 가지는 친구들은 valueBuffer에 2칸만 차지해서 들어갈 수 있습니다.
그럼 Line은? Line은 4개나 필요한데?!
이러한 경우에는 Swift는 Heap 메모리에 저장하게 됩니다. 아래의 그림과 같이 말이죠!

그래서 Heap메모리 영역에 저장해 두고, valueBuffer에는 그 영역을 가리키는 포인터를 저장해두게 됩니다.
여기서 또하나 알 수 있는것은 Point 타입과 Line타입의 저장 방식이 다르다는 것입니다. 그렇다면 Existential Container역시 이러한 차이를 관리해줄 필요가 있습니다.
이번에도 Table기반 메커니즘인 Value Witness Table입니다. Value Witness Table은 value에 대한 lifetime을 관리하는 역할을 합니다. 또한 Type마다 이 table을 가지고 있습니다. 즉 Point의 Value Witness Table도 있고, Line의 Value Witness Table도 있다는 것입니다.
이제 로컬변수의 life time을 보고 Value Witness Table의 동작 방식을 확인해 보겠습니다. Protocol type의 로컬변수의 life time 시작될 때, Swift는 Value Witness Table내부의 allocate 함수를 호출합니다.

이 함수는 Line의 Value Witness Table이므로 이전에 설명했던 Line에 대한 프로퍼티 들을 Heap영역에 저장하고, 그것을 가리키는 포인터를 valueBuffer에 둘 것 입니다.

이렇게 말이죠! 다음으로는 Swift는 로컬 변수를 초기화하는 assignment 소스에서 existential container로 값을 복사해 옵니다. Point와 같이 valueBuffer의 사이즈에 맞는 경우이므로 복사를 할때 existential container로 값을 복사해 오겠지만, Line의 경우에는 복사를 할때 Heap의 값을 복사해 오는 것입니다.

그렇게 프로그램이 계속 진행되고, 로컬변수 life time의 끝자락에 오게됩니다. 이때 Swift는 Value Witness Table에 있는 destruct entry를 호출합니다.
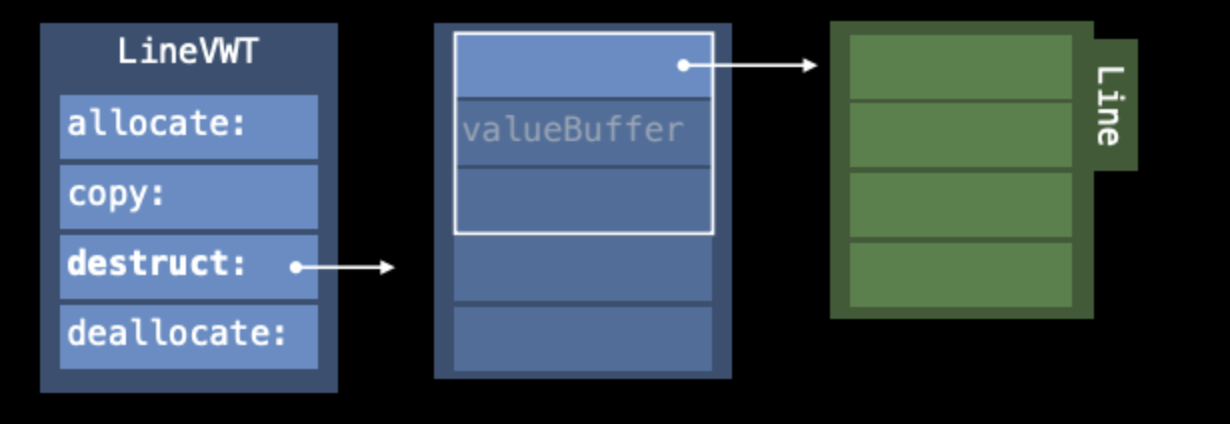
우리의 타입에 포함된 Value들의 Reference count를 감소(decrement) 시키거나 (Line은 Reference count를 감소시켜야할 것을 가지고 있지 않아셔 여기서는 필요가 없겠네요!) 하는 작업을 진행하게 됩니다.

그리고 제일 마지막에 Swift는 table에 있는 deallocate함수를 호출합니다. 그러면 그림과 같이 value에 대한 Heap 메모리를 deallocate하게 됩니다.
간단하게 살펴보면!

value witness table의 entry는 existential container에 reference 로 저장되고,

Protocol Witness Table 역시 마찬가지로 existential container에 reference를 저장합니다.
예시 코드를 보면서 이해해보도록 하겠습니다!
func drawACopy(local: Drawable) {
local.draw()
}
let val: Drawable = Point()
drawACopy(val)현재 val이라는 변수는 Drawable 프로토콜 타입이며 Point역시 Drawable 프로토콜을 준수하고 있기 때문에 val이라는 변수 안에 들어갈 수 있죠. 하지만 아래의 drawACopy(val)의 코드에서 함수로 들어가면 파라미터로 받은 Drawable 프로토콜 타입의 변수인 local의 draw() 메서드를 실행시키는 코드가 있습니다.
Swift는 직관적으로 저 draw가 Point의 draw인지, Line의 draw인지 알 수가 없겠죠?
이것을 Swift는 어떤 방식으로 해결하는지 한번 보겠습니다.
//Generated Code
struct ExistContDrawable {
var valueBuffer: (Int, Int, Int)
var vwt: ValueWitnessTable
var pwt: DrawableProtocolWitnessTable
}Swift 컴파일러는 우리를 위해서 이런 코드를 생성할 것 입니다.
existential container를 위해서 구조체를 하나 생성하였습니다. 3개를 저장할 수 있는 valueBuffer와 value witness table과 protocol witness table의 reference를 저장할 각각 프로퍼티 들이 존재하고 있습니다.
drawACopy(val)drawACopy 함수가 호출되면, argument를 받아서 함수로 전달합니다.
//Generated code
func drawACopy(val: ExistContDrawable)Generated code를 보면 Swift는 argument로 existential container를 받아 함수로 전달해주고 있습니다. 함수가 살행되는 순간
func drawACopy(local: Drawable)여기서의 local 파라미터는
let local = val이렇게 표현될 수 있겠죠! 그러면 Generated code는 어떨까요?
//Generated code
func drawACopy(val: ExistContDrawable) {
var local = ExistContDrawable()
}자 우선 Swift는 drawACopy의 argument로 existential container 구조체 타입을 넘깁니다. 그 과정에서 Swift는 Stack에 existential container를 만듭니다.
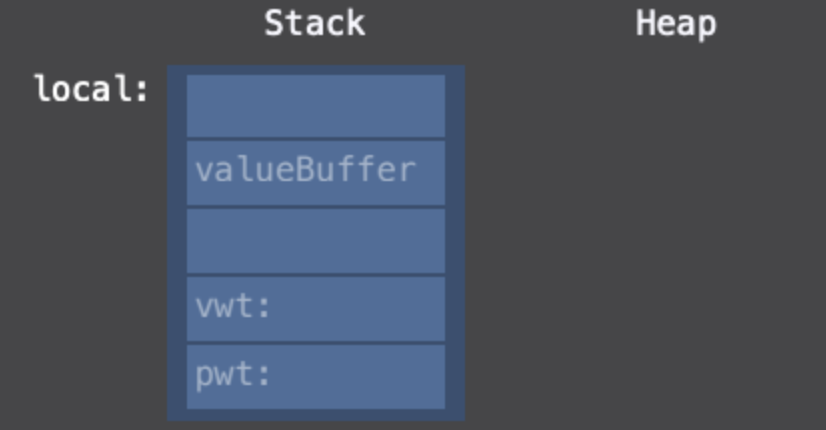
이런식으로 말이죠! 그런다음 existential container에서 vwt와 pwt를 읽어와 로컬 필드를 초기화 시켜줍니다.
//Generated code
func drawACopy(val: ExistContDrawable) {
var local = ExistContDrawable()
let vwt = val.vwt
let pwt = val.pwt
local.type = type
local.pwt = pwt
}다음으로는 필요한 경우 valueBuffer를 할당하고, 값을 복사하는 value witness table의 copy를 호출해줍니다.

Line일 경우 이렇게 생성이 되겠고, 아래의 그림을 보면 vwt, pwt 모두 Heap영역에 allocate가 된다는 사실을 알 수 있습니다.
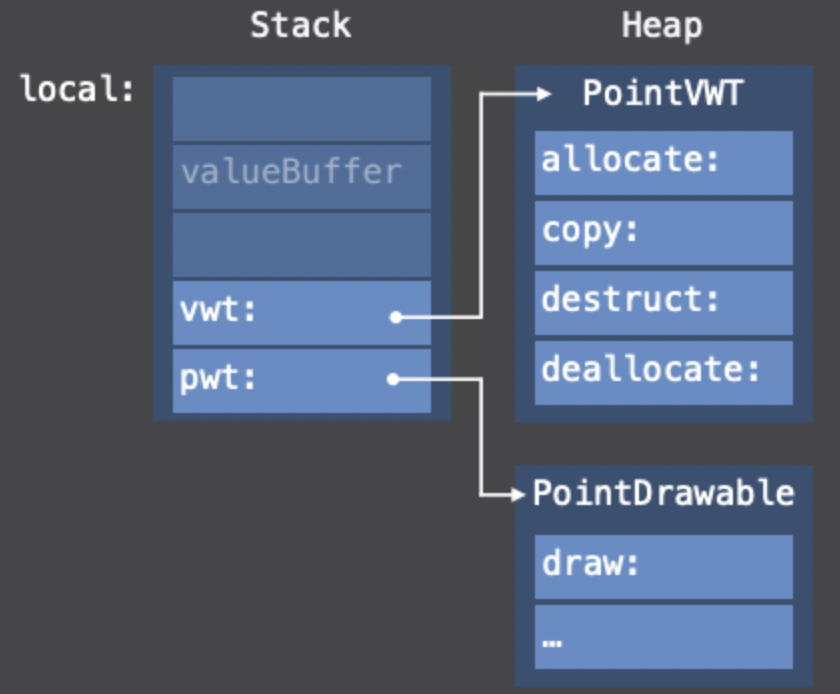
이렇게 되겠네요! 하지만 Point의 경우에는 별도로 valueBuffer에 대한 Heap allocate가 필요하지 않으므로,
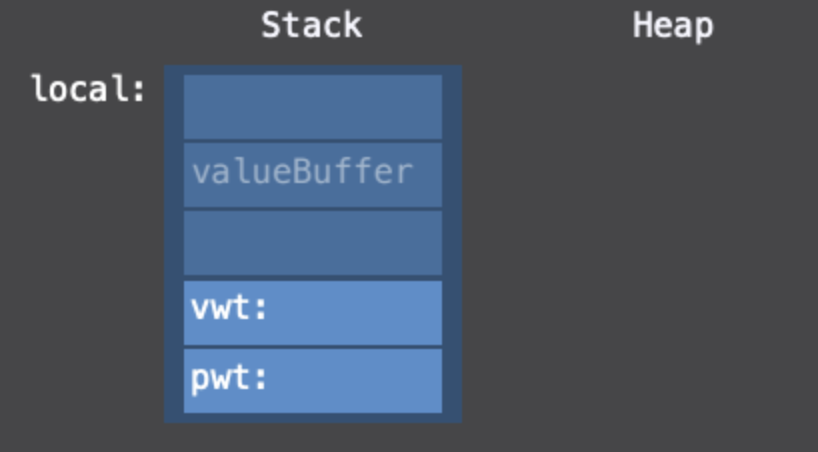
이런모습이겠네요! 이제 argument의 값을 local의 valueBuffer로 복사하는 과정이 있습니다. 한줄의 코드가 더 추가되겠죠!
//Generated code
func drawACopy(val: ExistContDrawable) {
var local = ExistContDrawable()
let vwt = val.vwt
let pwt = val.pwt
local.type = type
local.pwt = pwt
vwt.allocateBufferAndCopyValue(&local, val)
}
Point의 같은 경우에는 Heap allocation이 필요 없기 때문에 이러한 그림이 나오겠고, 그냥 argument의 값을 복사하여 local existential container의 valueBuffer에 넣을 수 있겠죠.
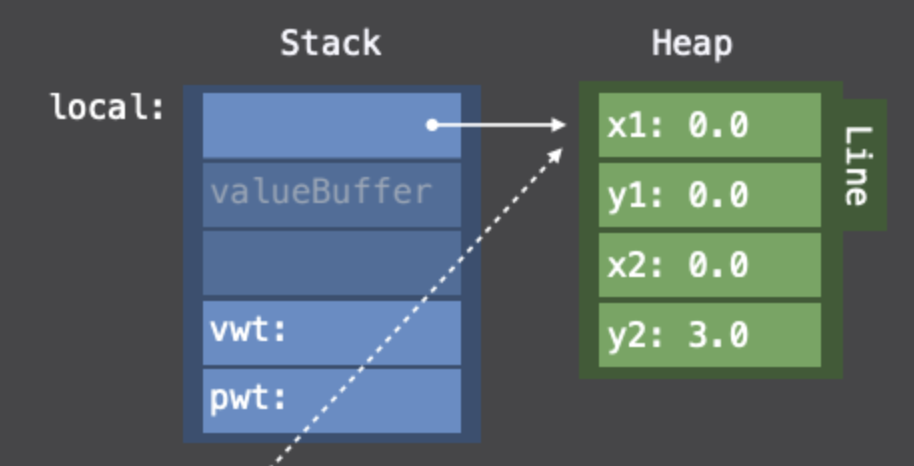
Line의 경우에는 위와 같은 그림이 나오게 되겠죠!
다음은 draw메서드가 실행되는 부분입니다.
local.draw()이 줄이 실행되면, Swift가 생성하는 코드는 다음과 같습니다.
//Generated code
func drawACopy(val: ExistContDrawable) {
var local = ExistContDrawable()
let vwt = val.vwt
let pwt = val.pwt
local.type = type
local.pwt = pwt
vwt.allocateBufferAndCopyValue(&local, val)
pwt.draw(vwt.projectBuffer(&local))
}
Swift는 existential container에 있는 Protocol witness table(pwt)을 조회합니다. 그리고 해당 table의 fixed offset에 있는 draw 메서드를 조회하여 그곳으로 jump합니다.
하지만 여기서 새로운 것이 하나 나옵니다 바로 projectBuffer라는 녀석입니다. 이게 왜 저기에 있을까요?
draw메서드는 인풋의 value로 주소가 들어올 것으로 예상하고 있습니다. value가 inline buffer에 맞는 (Point처럼) 작은 사이즈라면 이 주소는 existential container의 시작주소 이거나, Line처럼 inline valueBuffer에 맞지않는 큰 사이즈라면 이 주소는 Heap memory에 할당되어 있는 시작주소가 될 것 입니다.
따라서 이 Value witness function은 타입에 따라서 이러한 차이를 추상화 합니다.
draw메서드가 실행되고 끝나면, drawACopy 함수의 끝자락에 있다면, 파라미터로 받은 로컬 변수들이 이제 그 변수가 존재하는 영역을 벗어나기 직전이라는 의미입니다. 그래서 Swift는 value를 destruct하기 위한 value witness function 를 호출합니다.
//Generated code
func drawACopy(val: ExistContDrawable) {
var local = ExistContDrawable()
let vwt = val.vwt
let pwt = val.pwt
local.type = type
local.pwt = pwt
vwt.allocateBufferAndCopyValue(&local, val)
pwt.draw(vwt.projectBuffer(&local))
vwt.destructAndDeallocateBuffer(temp)
}Reference count를 decrement하고 value에 reference나 buffer가 존재한다면 그것을 deallocate시켜줍니다.

이런 그림이 나오겠네요! 함수가 종료되면, 여기서 이제 Stack도 제거가 될 것이죠. Stack에 만들어진 local existential container 또한 없어진 아무것도 없는 그림이 나오겠죠!
이러한 방식을 통해서 Value Type인 Struct가 Protocol과 함께 결합하여 Dynamic behavior, Dynamic polymorphism을 얻을 수 있게 되는 것입니다. 만약 dynamism이 필요하다면, 이전에 사용하였던 class를 상속받는 방법 보다는 이러한 Protocol을 활용한 방식이 더 좋은 비용이다! 라는 것을 말하는것 같습니다.
다음 예시 코드를 하나 더 보겠습니다!
struct Pair {
init(_ f: Drawable, _ s: Drawable) {
first = f
second = s
}
var first: Drawable
var second: Drawable
}first와 second라는 Drawable 프로토콜 타입인 두개의 저장 프로퍼티를 가지고 있습니다. Swift는 이 두개의 저장 프로퍼티를 어떻게 저장할까요?
var pair = Pair(Line(), Point())pair를 allocate하게 되면,

Swift는 필요한 두개의 existential container를 저장할 것 입니다. 그리고 두개의 existential container를 Pair 구조체로 감싸서 pair의 inline에 저장하게 됩니다. 프로그램은 이후에 다음 그림과 같이 초기화를 진행합니다.

이전에도 설명했듯 Line은 Heap영역에 저장될 것이고, Point는 valueBuffer에 맞기때문에 그대로 저장하게 됩니다.
또한 다형성을 지원하기 때문에 아래의 코드를 실행했을 때의 그림도 볼까요??
pair.second = Line()
이런 모습을 하고있겠죠! 하지만 이번에는 2개의 Heap allocation이 발생하고 있습니다.
Heap allocation의 비용에 대한 이야기를 해볼까요?
let aLine = Line(1.0, 1.0, 1.0, 3.0)
let pair = Pair(aLine, aLine)
let copy = pair이번에도 똑같이 2개의 Line을 사용하여 Pair를 초기화하는 모습입니다. 아까의 그림과 같겠죠? 하지만 문제는 copy를 생성했을 때입니다.
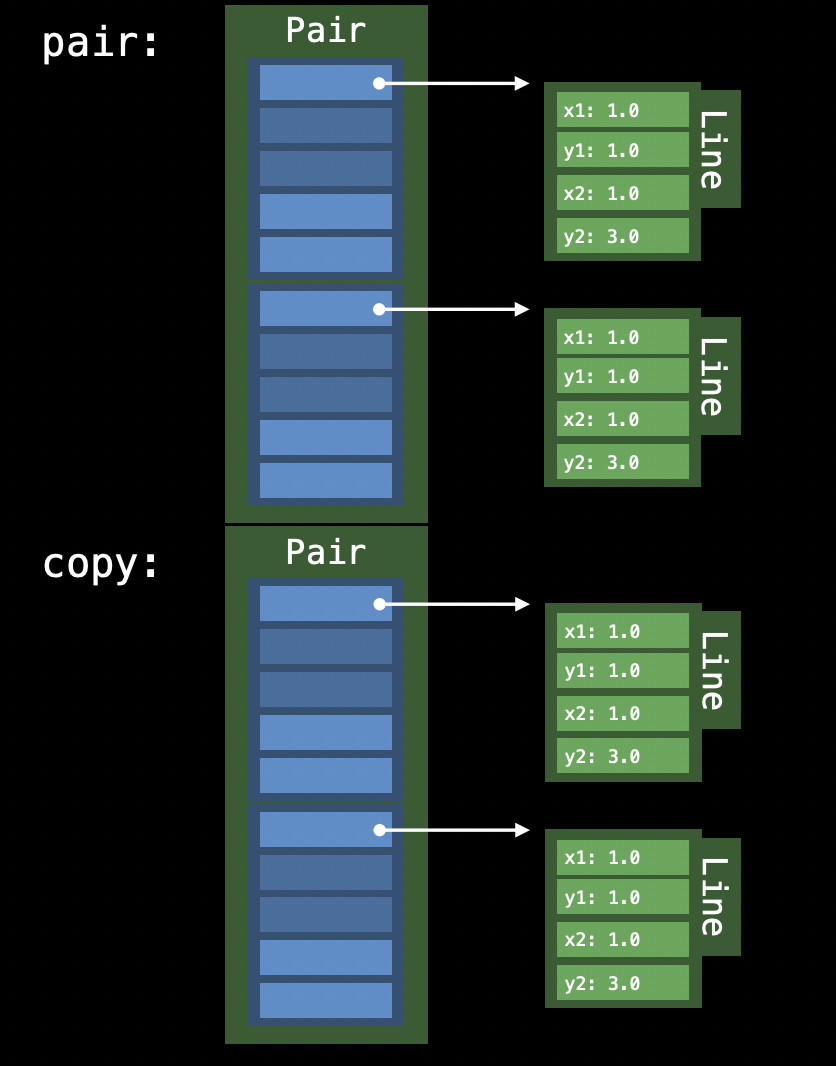
이런 그림을 볼 수 있겠죠! heap allocation은 많은 비용이 발생하는데 벌써 4개의 heap allocation이 보이고 있습니다.
이걸 개선해볼 수 있는 방법이 뭐가 있을까요?
existential container에는 3칸짜리 valueBuffer 공간이 있었죠, 그리고 reference는 그 공간에 맞을거구요 왜냐하면 reference는 기본적으로 한칸만 차지하기 때문이죠!

이렇게 말이죠! 그렇기 때문에 first를 복사한 second가 생성될 때에도 reference만 복제하면 된다는 의미입니다.

이런 그림이 나오겠네요! 그래서 이제 여기서 드는 비용은 추가적인 reference count만 발생하게 됩니다. 하지만 이러한 경우에는 만약에 아래와 같은 코드가 실행되면 어떻게 될까요?
second.x1 = 3.0
second의 x1을 바꾸는 동시에 first의 x1또한 영향을 받게 되겠죠! 즉, reference를 사용하면서 원본에 대한 공유 또한 함께 이루어지기 때문에 의도하지 않은 상태 공유가 일어날 수 있습니다. 이건 우리가 원하던 방식이 아닙니다!
여기서 사용할 수 있는 기술이 Copy and Write(COW) 라는 기술입니다.
class LineStorage { var x1, y1, x2, y2: Double }
struct Line : Drawable {
var storage : LineStorage
init() { storage = LineStorage(Point(), Point()) }
func draw() { … }
mutating func move() {
if !isUniquelyReferencedNonObjc(&storage) {
storage = LineStorage(storage)
}
storage.start = ...
}
}Line에 바로 저장소를 구현하는 방법 대신에 LineStorage라는 class를 생성하여 Line 구조체에 대한 모든 Field를 가지고 있게 합니다. 그리고 Line 구조체는 이 LineStorage를 참조하고 있게 합니다. 그리고 값을 읽어오고 싶을 때에는 그 Storage안에 있는 값을 읽어오면 됩니다.
그러나 수정이 필요한 경우에는 Value를 변경해야할 때에는 우선적으로 reference count를 확인해야 합니다. 그런데 reference count가 1보다 크다? 위의 코드에서 isUniquelyReferencedNonObjc가 호출되는 부분입니다. 이 메서드는 그저 하나의 기능을 합니다. Reference count가 1보다 큰가? 아니면 1과 같은가? 를 확인하는 용도이죠.
만약 1보다 큰다면, LineStorage에 대한 복사본을 생성하고, 그것을 변경(mutate)합니다.
아까전의 예시를 보면서 무슨일이 벌어지는지 한번 봅시다!
let aLine = Line(1.0, 1.0, 1.0, 1.0)
let pair = Pair(aLine, aLine)
let copy = pair처음에 Line을 생성하는
let aLine = Line(1.0, 1.0, 1.0, 1.0)가 호출되면, Heap영역에 Line이 생성됩니다. 우리는 이제 그것에 대한 reference만 저장하면 됩니다.
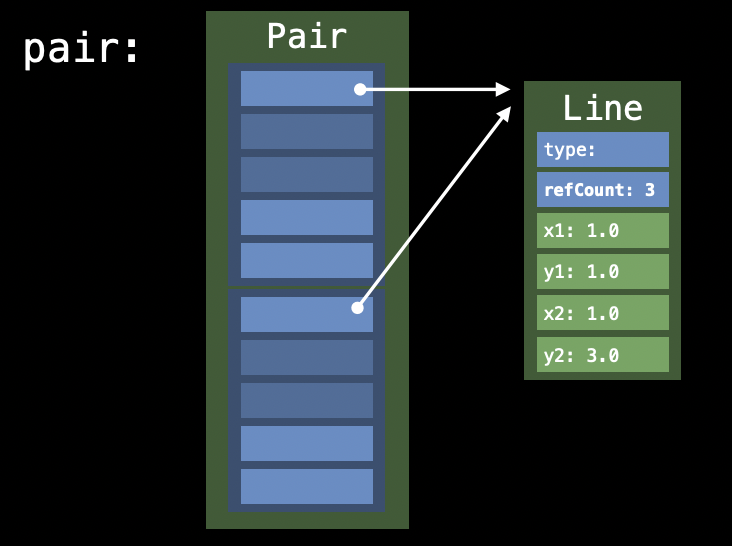
이렇게 말이죠! reference count가 3인 이유는 처음에 aLine이라는 변수를 생성할 때 참조 한번, pair를 만드는 과정에서 두번의 참조가 일어나기 때문에 refCount의 값은 3이 됩니다. 이후에 copy변수를 생성하는
let copy = pair위의 코드가 실행된다면... 역시 pair에 대한 참조를 복사하겠죠?

이런 그림이 나올것입니다! reference들만 복사되었습니다. 그리고 refCount도 2 증가했네요! 위의 Reference가 가리키고 있는 곳은 모두 아까 살펴보았던 LineStorage라는 class타입의 storage이겠죠? LineStorage가 class 타입이므로 모두 한 곳을 가리키고 있습니다.
그래서 이전에 살펴보았던 내부에서 값에대한 수정이 일어났을때, move 메서드를 실행하게 됩니다. move 메서드에서 isUniquelyReferencedNonObjc를 통해서 참조하고 있는 것이 하나인지, 하나 이상인지를 확인한 후 하나 이상일 때 그 storage에 대한 복사본을 만들고 난 후에 변경이 일어나게 됩니다.

이런 그림을 볼 수 있겠죠?!
이 방법이 heap allocation을 사용하였을때 보다 훨씬 저렴합니다.
Protocol Type - Small Value
자 이제 우리가 많은 값을 가지고 있지 않은 Protocol을 선언한다면, valueBuffer에 맞게 들어갈 것입니다. 이는 heap allocation이 필요없다는 의미이기도 하죠! 또한 reference 또한 포함하지 않을 것이므로, Reference counting도 없을 것입니다. 그래서 이건 매우 빠른 코드이죠!
그럼에도 Value witness table과 Protocol witness table 를 활용하여 dynamic dispatch와 dynamically polymorph behavior까지 할 수 있습니다.
Protocol Type - Large Value
Large Value일 경우에는 Protocol 타입의 변수를 초기화나 할당 할때마다 heap allocation이 발생합니다. value가 reference를 가지고 있을 경우에 reference counting이 발생할 수 있는 가능성 또한 있습니다. 하지만 COW 기술을 활용한 indirect storage를 활용할 경우에는 값비싼 heap allocation을 줄일 수 있습니다.
Protocol 타입을 사용하면서 Value type들의 dynamic polymerphism을 가능하게 하고, Witness table과 existential container를 활용한 indirection 또한 가능하게 했습니다. 또한 Large Value에 대한 Heap allocation이 발생하는데 그것 또한 앞서 살펴본 COW기술과 Indirection Storage를 활용하여 차이를 만들어낼 수 있었습니다.
다음 포스팅에서는 Generic을 활용하여 Performance 적인 측면을 어떻게 개선시킬 수 있을지 Understanding Swift Performance의 마지막 파트를 살펴보겠습니다!
developer.apple.com/videos/play/wwdc2016/416/
Understanding Swift Performance - WWDC 2016 - Videos - Apple Developer
In this advanced session, find out how structs, classes, protocols, and generics are implemented in Swift. Learn about their relative...
developer.apple.com
'WWDC' 카테고리의 다른 글
| Understanding Swift Performance - 3 (0) | 2021.03.07 |
|---|---|
| Understanding Swift Performance - 1 (0) | 2021.03.04 |